sqlalchemy를 사용해서 Dataframe을 DB로 Insert하기
2022. 11. 23. 23:09ㆍ[개발] 지식/Pandas
import pandas as pd
student = pd.DataFrame({
'year': ['2018', '2019', '2020', '2021'],
'name': ['a', 'b', 'c', 'd'],
'english_score': [98, 88, 75, 100],
'math_score': [70, 75, 93, 80]
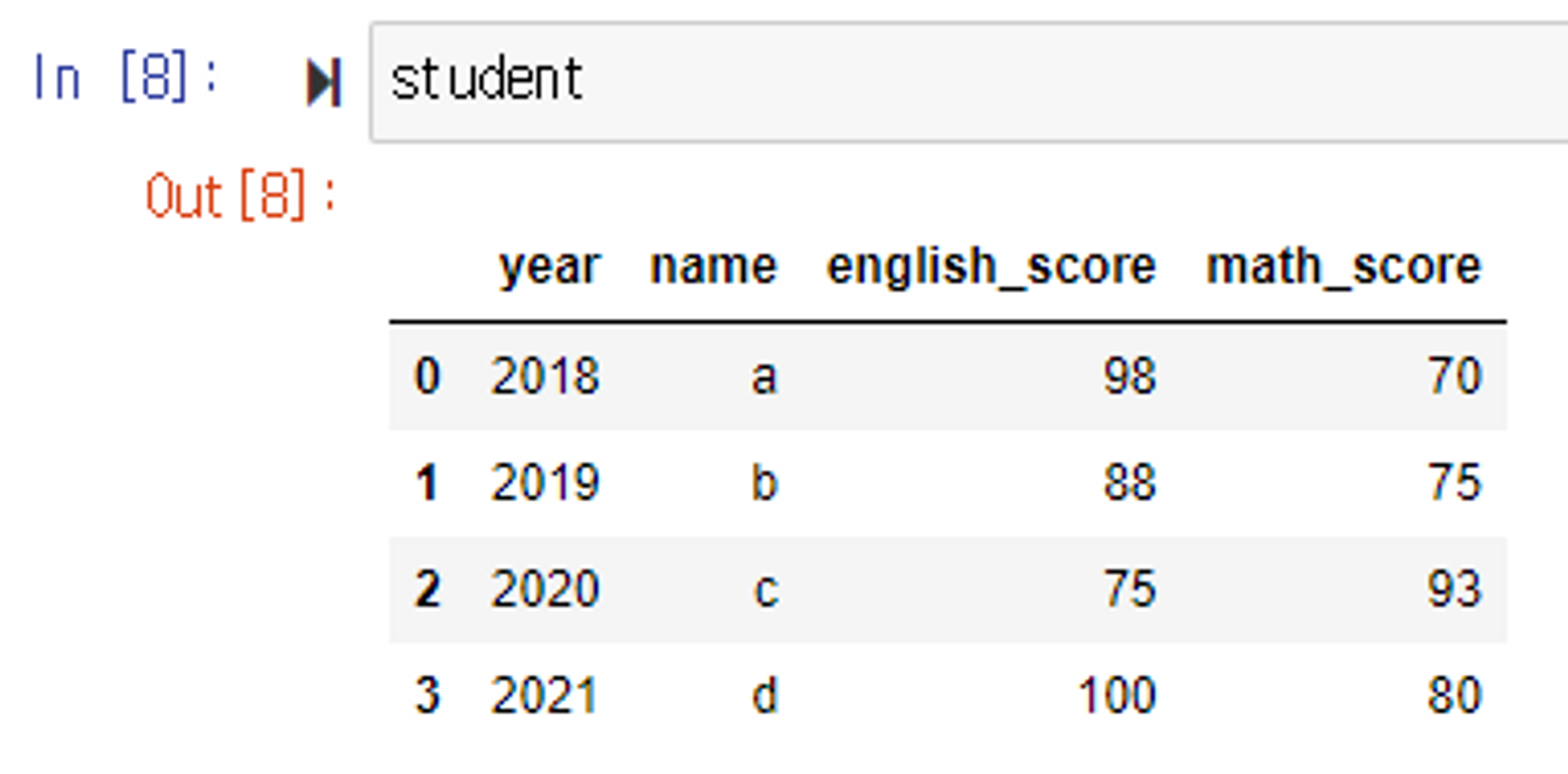
}, columns=['year', 'name', 'english_score', 'math_score'])테스트를 위해 Dataframe를 생성한다.
import sqlalchemy
from sqlalchemy import create_engine
engine = create_engine("postgresql://postgres:postgres@localhost:5432/postgres")sqlalchemy 모듈의 create_engine을 사용해서 DB engine을 생성한다.
student.to_sql(name = 'student',
con = engine,
schema = 'public',
if_exists = 'replace',
index = False,
index_label = 'id',
chunksize = 1,
dtype = {
'year': sqlalchemy.types.VARCHAR(4),
'name': sqlalchemy.types.VARCHAR(10),
'english_score': sqlalchemy.types.Float(precision=2),
'math_score': sqlalchemy.types.Float(precision=2)
}
)데이터프레임에는 to_sql이라는 함수를 제공한다. 여기에 sqlalchemy 엔진을 넣으면 테이블을 생성(필요시)해서 DB에 데이터를 넣어준다. 불필요하게 쿼리를 작성할 필요가 없으며, 데이터프레임의 컬럼을 스키마로 사용하여 테이블까지 생성해주니 매우 편리하게 사용할 수 있다. 관련 옵션은 아래와 같다.
- name : 테이블명
- con : sqlalchemy engine
- schema : 스키마
- if_exists : 테이블 생성규칙
- fail : 테이블이 이미 존재하면 실패처리
- replace : 테이블이 이미 존재하면 지우고 새로 생성
- append : 테이블이 이미 존재하면 이어서 데이터 삽입
- index : 테이블 인덱스 생성 여부
- index_label : 테이블 인덱스 생성시 해당되는 컬럼 지정
- chunksize : 한번에 insert하는 수
- dtype : 컬럼 및 타입 정의
Reference
[GPDB, PostgreSQL] Python DataFrame을 Sqlalchemy engine을 이용해 DB Table에 직접 쓰기 : df.to_sql()
지난 포스팅에서는 Python pandas DataFrame을 csv 파일로 다운로드 한 후에 로컬에서 PostgreSQL, Greenplum DB에 Copy해서 넣는 방법 (https://rfriend.tistory.com/457) 을 소개하였습니다. 이번 포스팅에서는 Python panda
rfriend.tistory.com
<