[Kubeflow Pipelines] Introduction
Kubeflow Pipelines 주요 컨셉과 목표 소개
Kubeflow Pilelines는 도커 컨테이너 기반의 이식 가능하고, 확장/축소가 유연한 머신러닝 워크 플로우 빌드 및 배포를 위한 플랫폼입니다.
Quickstart
첫번째 파이프라인을 실행하려면 pipelines quickstart guide를 참고하세요.
What is Kubeflow Pipelines?
Kubeflow Pipelines 플랫폼은 아래와 같이 구성됩니다:
- experiments, jobs, runs를 관리하고 추적할 수 있는 UI 제공
- 멀티 스텝 ML 워크플로우를 스케줄링 할 수 있는 엔진
- 파이프라인과 컴포넌트를 정의하고 조작할 수 있는 SDK
- SDK로 시스템과 인터랙션 할 수 있는 Notebooks
Kubeflow Pipelines의 목표는 아래와 같습니다:
- End-to-end 오케스트레이션 : 머신러닝 파이프라인의 오케스트레이션이 가능하고 단순화 할 수 있습니다.
- 쉬운 실험 : 수많은 아이디어와 기술을 시험할 수 있고 다양한 시도와 실험을 가능케 합니다.
- 쉬운 재사용 : 매번 리빌드(re-build) 하지 않고 end-to-end 솔루션을 신속하게 생성하기 위해 컴포넌트와 파이프라인을 재사용할 수 있습니다.
Kubeflow Pipelines는 Kubeflow의 코어 컴포넌트로써 또는 독립적인(standalone) 설치로 사용이 가능합니다.
kubeflow/pipelines#1700 의 이유로, Kubeflow Pipelines의 컨테이너 빌드는 현재 GCP(Google Cloud Platform) 자격 증명(credentials)만 가능합니다. 그래서 컨테이너 빌드는 Google Container Registry만 지원 가능합니다. 그러나 이미지를 가져오도록 자격 증명을 올바르게 설정한 경우 컨테이너 이미지를 다른 레지스트리에 저장할 수 있습니다.
What is a pipeline?
파이프라인이란 워크플로우의 모든 컴포넌트와 그것들을 어떻게 그래프로 표현할지에 대한 ML 워크플로우의 서술(표현)입니다(아래 파이프라인 그래프 스크린샷 참고) . 파이프라인은 각 컴포넌트의 인풋과 아웃풋, 그리고 파이프라인을 구동하기 위한 인풋 파라미터들을 정의하는 것 또한 포함하는 개념입니다.
일단 파이프라인을 정의하면, Kubeflow Pipelines UI에 이를 업로드하고 공유할 수 있습니다.
파이프라인 컴포넌트는 파이프라인 중 하나의 스텝을 수행하는 소스코드를 도커 이미지로 패키징 된 채로 내장하고 있습니다. 예를들어 하나의 컴포넌트는 데이터 전처리, 데이터 전달, 모델 훈련 등등을 수행할 수 있습니다.
컨셉 가이드는 pipelines 와 components 를 참고하세요.
Example of a pipeline
아래의 스크린샷과 코드는 xgboost-training-cm.py 파이프라인을 보여줍니다. 이 파이프라인은 CSV 포맷의 구조화된 데이터를 사용하여 XGBoost 모델을 생성합니다. GitHub 에서 소스코드와 다른 정보들을 볼 수 있습니다.
The runtime execution graph of the pipeline
아래 스크린샷은 파이프라인 런타임 실행 그래프를 UI에서 보여주는 화면입니다.
The Python code that represents the pipeline
아래 코드는 xgboost-training-cm.py 파이프라인을 정의하는 파이썬 코드입니다. 전체 코드는 GitHub에서 확인 가능합니다.
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
output='gs://your-gcs-bucket',
project='your-gcp-project',
cluster_name='xgb-%s' % dsl.RUN_ID_PLACEHOLDER,
region='us-central1',
train_data='gs://ml-pipeline-playground/sfpd/train.csv',
eval_data='gs://ml-pipeline-playground/sfpd/eval.csv',
schema='gs://ml-pipeline-playground/sfpd/schema.json',
target='resolution',
rounds=200,
workers=2,
true_label='ACTION',
):
output_template = str(output) + '/' + dsl.RUN_ID_PLACEHOLDER + '/data'
# Current GCP pyspark/spark op do not provide outputs as return values, instead,
# we need to use strings to pass the uri around.
analyze_output = output_template
transform_output_train = os.path.join(output_template, 'train', 'part-*')
transform_output_eval = os.path.join(output_template, 'eval', 'part-*')
train_output = os.path.join(output_template, 'train_output')
predict_output = os.path.join(output_template, 'predict_output')
with dsl.ExitHandler(exit_op=dataproc_delete_cluster_op(
project_id=project,
region=region,
name=cluster_name
)):
_create_cluster_op = dataproc_create_cluster_op(
project_id=project,
region=region,
name=cluster_name,
initialization_actions=[
os.path.join(_PYSRC_PREFIX,
'initialization_actions.sh'),
],
image_version='1.2'
)
_analyze_op = dataproc_analyze_op(
project=project,
region=region,
cluster_name=cluster_name,
schema=schema,
train_data=train_data,
output=output_template
).after(_create_cluster_op).set_display_name('Analyzer')
_transform_op = dataproc_transform_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=train_data,
eval_data=eval_data,
target=target,
analysis=analyze_output,
output=output_template
).after(_analyze_op).set_display_name('Transformer')
_train_op = dataproc_train_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=transform_output_train,
eval_data=transform_output_eval,
target=target,
analysis=analyze_output,
workers=workers,
rounds=rounds,
output=train_output
).after(_transform_op).set_display_name('Trainer')
_predict_op = dataproc_predict_op(
project=project,
region=region,
cluster_name=cluster_name,
data=transform_output_eval,
model=train_output,
target=target,
analysis=analyze_output,
output=predict_output
).after(_train_op).set_display_name('Predictor')
_cm_op = confusion_matrix_op(
predictions=os.path.join(predict_output, 'part-*.csv'),
output_dir=output_template
).after(_predict_op)
_roc_op = roc_op(
predictions_dir=os.path.join(predict_output, 'part-*.csv'),
true_class=true_label,
true_score_column=true_label,
output_dir=output_template
).after(_predict_op)
dsl.get_pipeline_conf().add_op_transformer(
gcp.use_gcp_secret('user-gcp-sa'))Pipeline input data on the Kubeflow Pipelines UI
아래 스크린샷은 Kubeflow Pipelines UI에서 파이프라인의 run을 설정하는 화면입니다. 파이프라인을 정의하는 당신의 코드에서 어떤 파라미터가 UI에 보일지를 지정할 수 있습니다. 또한 디폴트 값 세팅도 가능합니다.
Outputs from the pipeline
아래 스크린샷은 Kubeflow Pipelines UI에서 볼수 있는 output의 예시입니다.
Prediction results:
Confusion matrix:
Receiver operating characteristics(ROC) curve:
Architectural overview
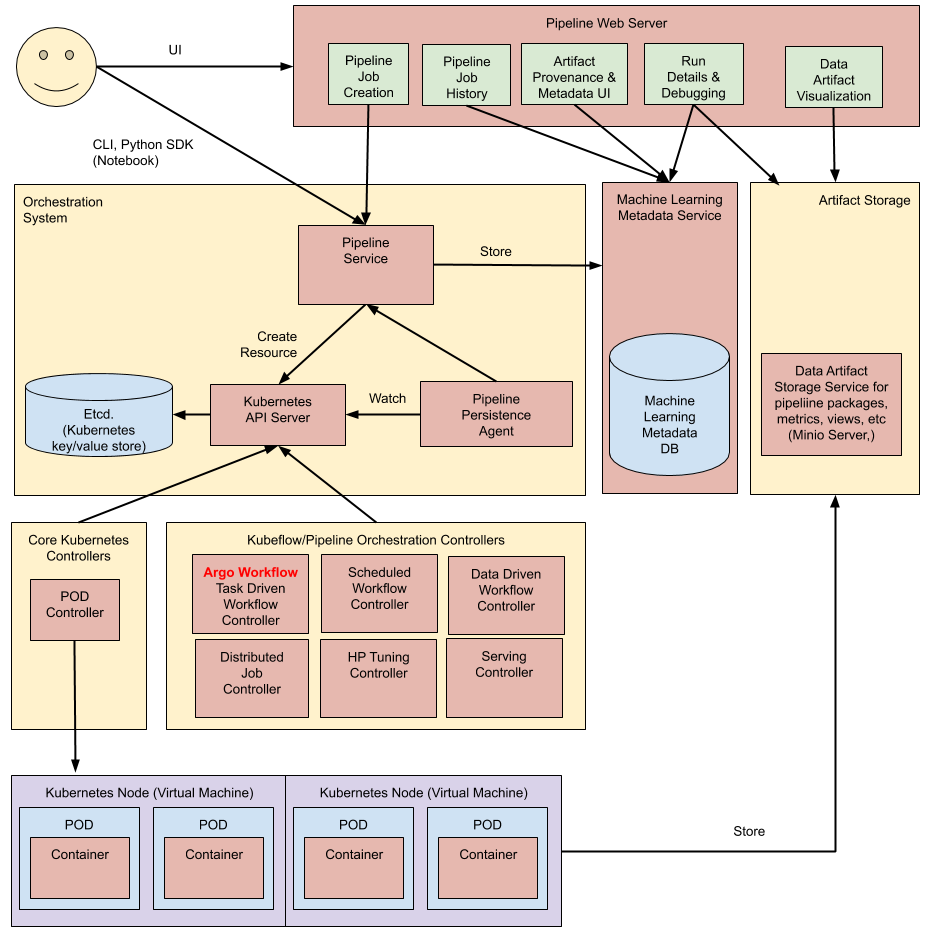
하이 레벨 차원에서, 파이프라인 진행 절차는 아래와 같습니다:
- Python SDK: 당신은 Kubeflow Pipelines 도메인 특화 언어(DSL)를 사용해서 파이프라인을 명시하거나 컴포넌트들을 생성합니다.
- DSL compiler: DSL compiler는 당신의 파이썬 코드를 YAML(static configuration)로 바꿔 줍니다.
- Pipeline Service: 당신은 YAML로부터 파이프라인 run을 생성하기 위해 Pipeline Service를 호출합니다.
- Kubernetes resources: Pipeline Service는 파이프라인을 구동하기 위해, 필수적인 쿠버네티스 리소스들을 생성하는 Kubernetes API를 호출 합니다.
- Orchestration controllers: 파이프라인을 완성하기 위해 필요한 컨테이너를 구동하는 오케스트레이션 컨트롤러 셋입니다. 해당 컨테이너들은 가상머신의 쿠버네티스 팟 안에서 구동됩니다. 예를들면 task-driven workflow를 지휘하는 Argo Workflow 컨트롤러를 들 수 있습니다.
- Artifact storage: 팟(Pods)은 두 종류의 데이터를 저장합니다.
- Metadata: Experiments, jobs, pipeline runs, single scalar metrics. 메트릭 데이터는 정렬과 필터링 목적으로 집계됩니다. Kubeflow Pipelines는 메타 데이터를 MySQL 데이터베이스에 저장합니다.
- Artifacts: 파이프라인 패키지들, views, 큰 규모의 메트릭들(time series). 파이프라인 run을 디버그 하거나 개별 run 성능을 검증하기위해 큰 규모의 메트릭들을 사용합니다. Kubeflow Pipelines은 Minio server나 Cloud Storage 같은 아티팩트 스토어에 아티팩트들을 저장합니다.
MySQL 데이터베이스와 Minio 서버는 모두 Kubernetes Persistent Volume 하위 시스템에서 지원됩니다.
- Persistence agent and ML metadata: Pipeline Persistence Agent는 Pipeline Service에 의해 생성된 리소스들을 보고, ML Metadata Service에서 이러한 리소스들의 상태를 유지합니다. Pipeline Persistence Agent는 input과 output 뿐만 아니라 실행되는 컨테이너 세트를 기록합니다. input과 output은 각 컨테이너의 파라미터 또는 데이터 아티팩트 URI로 구성됩니다.
- Pipeline web server: 파이프라인 웹 서버는 관련된 뷰(현재 구동중인 파이프라인 리스트, 파이프라인 실행 히스토리, 데이터 아티팩트 리스트, 개별 파이프라인 run에 대한 디버깅 정보 또는 실행 상태)를 보여주는 다양한 서비스로부터 데이터를 모읍니다.